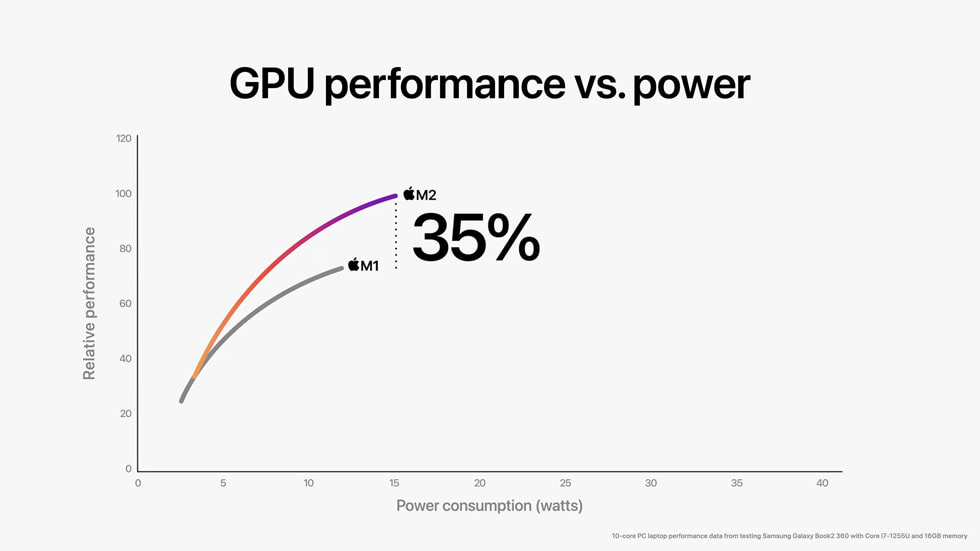
NVIDIA’s Blackwell platform is rewriting the economics of AI inference, delivering a 10x reduction in token costs that could upend industries from healthcare to gaming. By optimizing compute efficiency at the hardware-software stack level, Blackwell isn’t just faster—it’s fundamentally more cost-effective, enabling providers to deploy large-scale models without proportional cost spikes.
The impact is already tangible. Healthcare automation firm Sully.ai, for instance, cut inference costs by 90% after migrating to Baseten’s Model API on Blackwell GPUs. The shift from proprietary models to open-source frameworks, combined with NVIDIA’s NVFP4 data format and TensorRT-LLM optimizations, delivered 2.5x better throughput per dollar and 65% faster response times than the previous Hopper generation. For physicians, that translates to 30 million minutes reclaimed from manual data entry—time now spent on patient care rather than documentation.
Why Blackwell’s Efficiency Matters
At its core, Blackwell’s advantage stems from a co-designed hardware-software approach that minimizes wasted compute cycles. Unlike traditional GPUs, which rely on general-purpose acceleration, Blackwell integrates low-precision NVFP4 format support, TensorRT-LLM optimizations, and NVIDIA Dynamo’s dynamic inference engine. The result? Up to 4x lower token costs for providers like DeepInfra, which now charges as little as 5 cents per million tokens—down from 20 cents on Hopper. For AI-driven gaming platforms like Latitude (behind Voyage RPG), this means handling massive traffic spikes without latency degradation or cost explosions.

Key Specs Behind the Efficiency
- Compute: Blackwell’s GB200 NVL72 system delivers 10x better performance per watt compared to Hopper, with specialized accelerators for sparse matrix operations (critical for MoE models).
- Precision: Native support for NVFP4 (4-bit floating-point) reduces memory bandwidth and compute requirements without sacrificing accuracy.
- Software Stack: TensorRT-LLM and Dynamo optimize model loading, execution, and memory usage, cutting overhead by up to 70% in some workloads.
- Networking: Blackwell integrates NVLink 5.0 for ultra-low-latency multi-GPU communication, essential for distributed inference.
- Power Efficiency: The architecture achieves 2x better energy efficiency per AI operation, a critical factor for cloud providers scaling inference workloads.
These improvements aren’t just theoretical. Fireworks AI, which powers multi-agent workflows for clients like Sentient Labs, reported 25–50% cost savings on Blackwell compared to Hopper. During a recent viral launch, the platform processed 5.6 million queries in a week—a workload that would have been prohibitively expensive on prior hardware.
Real-World Tradeoffs and Unknowns
The efficiency gains come with tradeoffs. Blackwell’s optimizations are model-specific, meaning legacy workloads may not see proportional benefits. Additionally, the NVFP4 format requires retraining or quantization for existing models, a barrier for some enterprises. Early adopters like Together AI (hosting Decagon’s voice support stack) mitigated this by combining open-source models with Blackwell’s speculative decoding—a technique that predicts likely next tokens to reduce compute time.
Looking ahead, NVIDIA’s upcoming Rubin platform is poised to extend these trends, with rumors suggesting another 10x improvement in token cost efficiency. But for now, Blackwell is already proving that AI’s scalability ceiling has been raised—not just in performance, but in economic viability.
For industries where every token counts—whether in automated healthcare documentation, real-time gaming interactions, or enterprise AI agents—Blackwell’s arrival marks a turning point. The question isn’t just how fast* AI can process data, but how affordably* it can do so at scale.