Artificial intelligence inference is getting cheaper—sometimes dramatically so. New benchmarks from Nvidia show that four leading inference providers have cut per-token costs by 4x to 10x by deploying open-source models on Blackwell hardware, paired with precision optimizations and specialized software stacks. The results span industries from healthcare to gaming, where inference economics now determine whether AI projects scale from prototypes to production.
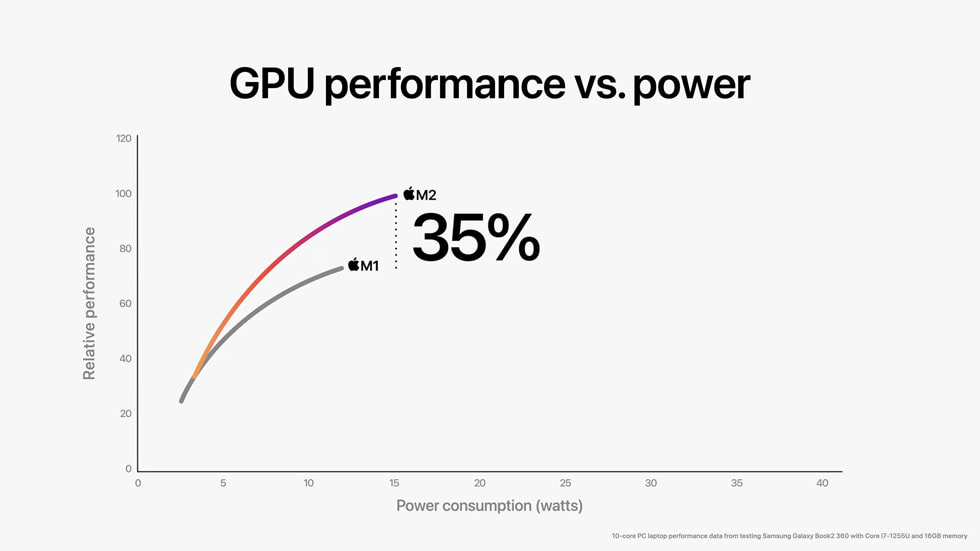
The catch? Hardware alone doesn’t unlock the full savings. While Blackwell’s NVL72 architecture and NVLink interconnect deliver up to 2x cost reductions on their own, reaching the higher end of the spectrum—like Sully.ai’s 10x reduction in healthcare AI—requires adopting low-precision formats such as NVFP4 and replacing proprietary models with open-source alternatives. The economics defy intuition: higher-performance infrastructure isn’t just a cost—it’s a multiplier for efficiency.
Nvidia’s analysis highlights four deployments where the combination of hardware, software, and model choices drove significant savings. Each case demonstrates how precision formats, model architecture, and software integration create compounding effects that hardware improvements alone cannot match.
The 10x Factor: Precision and Open-Source Models
Sully.ai’s healthcare AI reduced inference costs by 90%—a 10x improvement—by switching from proprietary models to open-source alternatives running on Baseten’s Blackwell-powered platform. The move not only cut costs but also returned over 30 million minutes to physicians by automating medical coding and note-taking. This wasn’t just about hardware; it was about eliminating the premium pricing of closed-source APIs and leveraging open models that now rival frontier-level performance.
Latitude’s AI Dungeon platform saw a similar transformation. The company reduced gaming inference costs by 4x by transitioning from Nvidia’s Hopper platform to Blackwell, then further halving costs by adopting Blackwell’s native NVFP4 low-precision format. The result? Costs per million tokens dropped from 20 cents on Hopper to 5 cents on Blackwell with NVFP4. Hardware improvements alone delivered 2x gains, but the precision format change doubled that efficiency.
Why 4x Isn’t Always Enough
The range between 4x and 10x cost reductions isn’t random—it reflects how different technical choices interact. Three key factors drive the difference
- Precision formats: NVFP4 reduces the bits required for model weights and activations, allowing more computation per GPU cycle while maintaining accuracy. For mixture-of-experts (MoE) models—where only a subset of the model activates per request—this format delivers outsized efficiency gains.
- Model architecture: MoE models benefit from Blackwell’s NVLink fabric, which enables rapid communication between specialized sub-models. Dense models, which activate all parameters for every inference, don’t leverage this architecture as effectively.
- Software stack integration: Nvidia’s co-designed approach—pairing Blackwell hardware with tools like Dynamo and TensorRT-LLM—creates performance deltas. Providers using alternative frameworks like vLLM may see lower gains.
Workload characteristics also play a role. Reasoning models, which generate more tokens to reach better answers, benefit from Blackwell’s ability to process extended token sequences efficiently. Disaggregated serving—where context prefill and token generation are handled separately—makes these workloads cost-effective.
Who Should Migrate—and When?
Not every AI deployment will see 10x cost reductions. Enterprises must evaluate their workloads before committing to Blackwell-based inference. High-volume, latency-sensitive applications—like Sully.ai’s healthcare automation or Decagon’s voice customer support—are prime candidates. These use cases process millions of requests monthly, where even small latency increases can erode user trust.
Teams with lower-volume workloads or applications with relaxed latency requirements may achieve meaningful savings through software optimizations or model switching before upgrading hardware. For example, running open-source models on existing infrastructure could deliver half the potential cost reduction without new investments.
Testing is critical. Published benchmarks often reflect ideal conditions, but real-world performance varies. Teams should run actual production workloads across multiple Blackwell providers to measure performance under their specific usage patterns and traffic spikes. Provider selection matters too—some deploy Nvidia’s integrated stack (Dynamo + TensorRT-LLM), while others use frameworks like vLLM. Performance deltas exist between these configurations.
Finally, the economic equation extends beyond cost per token. Managed services from cloud providers like AWS or Azure may have higher per-token costs but lower operational complexity. Specialized inference providers offer optimized deployments but require additional vendor management. Teams must calculate total cost—including operational overhead—to determine the best approach for their needs.
For enterprises evaluating Blackwell, the message is clear: hardware is just the beginning. Precision formats, open-source models, and software integration are the multipliers that turn cost reductions from possible to transformative.